BIG
Study. X-ray 사진을 분석한 폐렴 진단(With Kaggle)
[코드 분석과 흐름]
[1] 사전 정리
- X-ray 사진에서 혼탁 현상이 없으면 정상이고 있으면 폐렴이다.
- 데이터셋은 train, test, val로 구성되며, 총 5,863개의 X-Ray 이미지와 2개의 카테고리(폐렴/정상)가 있다.
- 이 데이터는 1~5세 소아 환자들의 X-ray 데이터이다.
[2] 필요한 라이브러리 import 하기
import pandas #pandas : dataframe 데이터 타입을 참고하여 테이블 형식의 데이터를 다루기 위해 사용하는 라이브러리
import os #os : 파일 안에 있는 데이터를 불러올 때 glob랑 같이 사용
import glob #glob : 파일디렉토리를 불러올 때 os랑 같이 사용
import tensorflow as tf #tensorflow : 사람이 할 수 없는 기계학습 작업을 할 때 사용하는 플랫폼
from keras.applications import ResNet50V2 #ResNet50V2 : 이미지 분류할 때 인식하기 위해서 사용하는 라이브러리
import numpy as np # 수치 연산을 수행하는 선형대수 라이브러리
import matplotlib.pyplot as plt
import pandas as pd
from keras.preprocessing.image import ImageDataGenerator # 여러 함수를 통해 이미지 로드 및 이미지 증식(크기 조절)
import keras
import seaborn as sns # 통계적으로 시각화하는 패키지
import cv2 # 이미지 출력을 위한 방법, 알려진 값을 가진 두 점 사이 어느 지점의 값이 얼마일지를 추정하는 '보간법'
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Dropout
from tensorflow.keras.models import Sequential
from sklearn.metrics import classification_reportPooling Layer
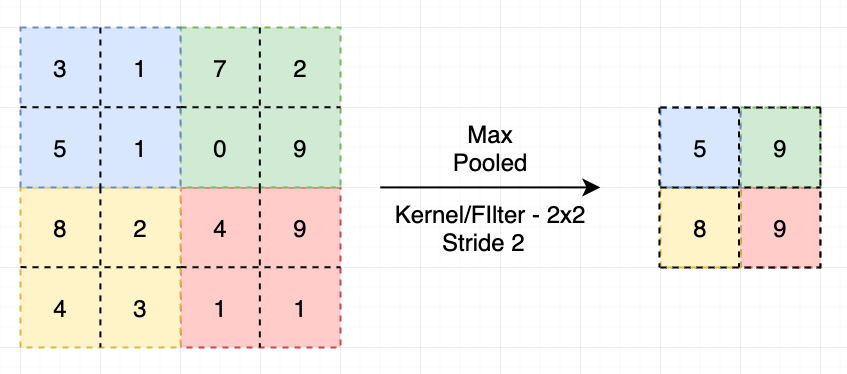
1) Pooling을 해야하는 이유 : 필터가 많을수록 정확도가 높아지는데, 필터가 늘어나면 Feature Map도 들어난다. 이 말은 모델의 차원도 늘어난다는 것이고 파라미터의 수도 늘어나기 때문에 차원을 감소시키기 위해서 Pooling Layer을 사용한다.
2) 자주 사용되는 Pooling의 종류
(1) MaxPooling : 영역에서 최댓값을 찾는 방법
- 위치에 상관없이 눈, 코, 입 등의 Feature를 인식할 수 있도록 해준다.
(2) GlobalAveragePooling : 영역에서 평균값을 찾는 방법
[3] 데이터 수집
- kaggle 환경에 데이터 파일이 올라가 있기 때문에 그 폴더 안에 있는 데이터를 불러와서 전처리 작업을 하면 된다.
- 그러기 위해서는 먼저 그 폴더 경로를 설정해서 데이터를 끌어와야 한다.
- 경로를 설정하는 코드에서 에러가 난다면 glob도 써보자.
3-1) 파일에 따른 데이터셋 분리와 파일 경로 저장

main_path = "../input/chest-xray-pneumonia/chest_xray/"- 'chest_xray'안에 있는 훈련, 테스트, 검증 3개의 데이터의 위치를 불러와서 main_path에 저장한다.
train_path = os.path.join(main_path,"train")
test_path=os.path.join(main_path,"test")
val_path=os.path.join(main_path,"val")
pneumonia_train_images = glob.glob(train_path+"/PNEUMONIA/*.jpeg")
normal_train_images = glob.glob(train_path+"/NORMAL/*.jpeg")
pneumonia_val_images = glob.glob(val_path+"/PNEUMONIA/*.jpeg")
normal_val_images = glob.glob(val_path+"/NORMAL/*.jpeg")
pneumonia_test_images = glob.glob(test_path+"/PNEUMONIA/*.jpeg")
normal_test_images = glob.glob(test_path+"/NORMAL/*.jpeg")- main_path의 train, test, val의 위치도 각각 train_path, test_path, val_path로 저장한다.
- train_path, test_path, val_path 안에 있는 NORMAL과 PNEUMONIA 폴더를 각각 나누어서 아래의 6개의 이미지 데이터셋으로 분류한다.
- pneumonia_train_images : 훈련용 폐렴 이미지
- normal_train_images : 훈련용 정상 이미지
- pneumonia_val_images : 검증용 폐렴 이미지
- normal_val_images : 검증용 정상 이미지
- pneumonia_test_images : 테스트용 폐렴 이미지
- normal_test_images : 테스트용 정상 이미지
3-2) 폐렴과 정상의 class부여
data = pd.DataFrame(np.concatenate([[0]*len(normal_train_images), [1]*len(pneumonia_train_images)]),columns=["class"])
# class라는 컬럼에 훈련용 정상 데이터는 0, 훈련용 폐렴 데이터는 1로 결합하여 판다스의 dataframe 형식으로 data변수에 저장- np.concatenate : 배열 데이터 결합
- 폐렴 : 1
- 정상 : 0
[4] 데이터 전처리
- EDA(탐색적 데이터 분석) : 데이터를 분석하기 전에 그래프나 통계적인 방법으로 자료를 직관적으로 바라보는 분석 방법
- 우리는 EDA를 사용하였다.
4-1) class에 따른 데이터 시각화
sns.countplot(data['class'],data=data)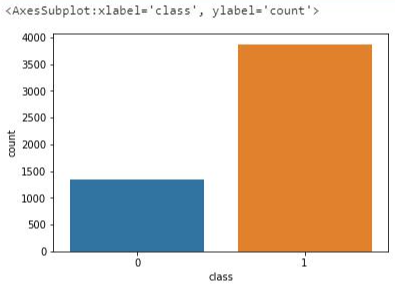
- 앞에서 부여했던 class를 그래프로 나타내었다.
- 폐렴 데이터가 정상 데이터보다 많은 것을 알 수 있다.
4-2) 훈련용 x-ray 사진을 폐렴과 정상으로 분류하여 시각화
fig, axes = plt.subplots(nrows=1, ncols=6, figsize=(15,10), subplot_kw={'xticks':[], 'yticks':[]})
for i, ax in enumerate(axes.flat):
img = cv2.imread(normal_train_images[i])
img = cv2.resize(img, (512,512))
ax.imshow(img)
ax.set_title("Normal")
fig.tight_layout()
plt.show()
fig, axes = plt.subplots(nrows=1, ncols=6, figsize=(15,10), subplot_kw={'xticks':[], 'yticks':[]})
for i, ax in enumerate(axes.flat):
img = cv2.imread(pneumonia_train_images[i])
img = cv2.resize(img, (512,512))
ax.imshow(img)
ax.set_title("Pneumonia")
fig.tight_layout()
plt.show()
- 정상인 x-ray 사진과 폐렴인 x-ray 사진을 분류하여 시각화하였다.
- subplots를 사용하여 1행 6 열인 grid 형태로 만들고 xticks와 yticks를 이용하여 사이 간격을 주었다.
- 반복문이 2개인 이유는 정상 x-ray와 폐렴 x-ray를 따로 반복문을 돌려서 출력했기 때문이다.
4-3) 훈련용 x-ray 사진에서 뼈 모양으로 추출하여 폐렴과 정상으로 분류하여 시각화
fig, axes = plt.subplots(nrows=1, ncols=6, figsize=(15,10), subplot_kw={'xticks':[], 'yticks':[]})
for i, ax in enumerate(axes.flat):
img = cv2.imread(pneumonia_train_images[i])
img = cv2.resize(img, (512,512))
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.Canny(img, 80, 100)
ax.imshow(img)
ax.set_title("Pneumonia")
fig.tight_layout()
plt.show()
fig, axes = plt.subplots(nrows=1, ncols=6, figsize=(15,10), subplot_kw={'xticks':[], 'yticks':[]})
for i, ax in enumerate(axes.flat):
img = cv2.imread(normal_train_images[i])
img = cv2.resize(img, (512,512))
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.Canny(img, 80, 100)
ax.imshow(img)
ax.set_title("Normal")
fig.tight_layout()
plt.show()
- 이번에도 정상 x-ray와 폐렴 x-ray를 분류하여 시각화하였으나 정상 x-ray에 비해 폐렴 x-ray는 뼈의 모양이 잘 보이지 않는다.
4-3) 검증 정확도를 높이기 위해 검증 데이터 추가하기
val_Pneumonia = len(os.listdir(val_path+'/PNEUMONIA'))
val_Normal =len(os.listdir(val_path+'/NORMAL'))
print(f'len(val_Normal) = {val_Normal},len(val_Pneumonia)={val_Pneumonia}')
from distutils.dir_util import copy_tree
copy_tree(main_path,'temp')path = './temp/chest_xray'train_path = os.path.join(path,"train")
test_path=os.path.join(path,"test")
val_path=os.path.join(path,"val")val_Pneumonia = len(os.listdir(val_path+'/PNEUMONIA'))
val_Normal =len(os.listdir(val_path+'/NORMAL'))
print(f'len(val_Normal) = {val_Normal},len(val_Pneumonia)={val_Pneumonia}')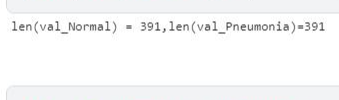
- 원래 8개밖에 없던 이미지 데이터를 더 추가해서 검증 정확도를 높인다.
- 로컬 드라이브로 데이터를 처리한다.
4-4) 이미지 증강
train_Datagen = ImageDataGenerator(
rescale =1/255,
# shear_range=10,
zoom_range = 0.2,
width_shift_range=0.2,
height_shift_range=0.2,
# rotation_range=20,
fill_mode = 'nearest',
)
val_datagen = ImageDataGenerator(
rescale =1/255,
# shear_range=10,
# zoom_range = 0.2,
# horizontal_flip = True,
# width_shift_range=0.2,
# height_shift_range=0.2,
# rotation_range=20,
# fill_mode = 'nearest',
)- keras의 ImageDataGenerator를 이용하여 데이터 확대를 위한 데이터 생성을 수행한다.
- 학습 도중 이미지에 임의 변경 및 정규화를 적용한다.
[5] 데이터 모델링
5-1) Sequential 모델링
input_shape = (512,512,3)- 3차원으로 배열을 입력받는다.
5-2) 층을 쌓는다.
base_model = tf.keras.applications.ResNet50V2(weights='imagenet', input_shape=input_shape, include_top=False)
for layer in base_model.layers:
layer.trainable = False
model = Sequential()
model.add(base_model)
model.add(GlobalAveragePooling2D())
model.add(Dense(128, activation = 'relu',kernel_regularizer= keras.regularizers.l2(l2=0.1)))
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
5-3) 테스트 데이터를 검증 데이터로 사용할 수 있도록 변경한다.
train_generator=train_Datagen.flow_from_directory(
train_path,
target_size=(512,512),
batch_size= 32,
class_mode='binary'
)
validation_generator = val_datagen.flow_from_directory(
test_path,
target_size=(512,512),
batch_size=32,
class_mode='binary'
)
test_generator = val_datagen.flow_from_directory(
val_path,
target_size=(512,512),
batch_size=32,
class_mode='binary'
)
[6] 모델 학습
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
initial_learning_rate = 1e-3
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=755,
decay_rate=0.9,
staircase=True)
model.compile(optimizer= Adam(lr_schedule), loss='binary_crossentropy', metrics=["accuracy"])
#callback = tf.keras.callbacks.EarlyStopping(monitor='accuracy', patience=4)
history = model.fit(train_generator,
epochs=10,
steps_per_epoch = 4834 // 32,
validation_data = validation_generator,
validation_steps = 624 // 32)
[7] 모델 평가
7-1) 정확도 확인하기
model.evaluate(test_generator)[1]
model.evaluate(validation_generator)[1]

- test 데이터의 정확도는 94% 정도이고, 검증 정확도는 88%
7-1) epoch를 무조건 많이 돌린 후, 특정 시점에서 멈추기(Early Stopping)
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1)
history_new = model.fit(train_generator,
epochs=10,
steps_per_epoch = 4834 // 32,
validation_data = validation_generator,
validation_steps = 624 // 32,
callbacks=[es])
- 위 사진을 보면 epoch가 5일 때 early stopping이라고 출력하면서 멈췄다.
7-2) 훈련 과정 시각화
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']plt.figure(figsize=(15,10))
plt.subplot(2, 2, 1)
plt.plot(accuracy, label = "Training accuracy")
plt.plot(val_accuracy, label="Validation accuracy")
plt.ylim(0.8, 1)
plt.legend()
plt.title("Training vs validation accuracy")
plt.subplot(2,2,2)
plt.plot(loss, label = "Training loss")
plt.plot(val_loss, label="Validation loss")
plt.ylim(0, 0.5)
plt.legend()
plt.title("Training vs validation loss")
plt.show()- 정확도 : accuracy
- 손실 : loss
7-3) 테스트용과 검증용 정확도 한번 더 확인하기
model.evaluate(validation_generator)[1]
model.evaluate(test_generator)[1]
- 위에서 Early Stopping으로 훈련을 한번 더 했기 때문에 정확도가 더 올라감
- 일단 실제 데이터 분석 결과 y_true에 넣어준다.
print(classification_report(y_true,y_pred))
- 결과적으로 이미지 분류기의 정확도는 97%가 나오는 것을 알 수 있었다.
📎 사용한 데이터셋 : https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia
'🖊️Data Analysis > 📌 DL)X-ray 사진을 이용한 폐렴 진단' 카테고리의 다른 글
| [Python] X-ray 사진을 분석한 폐렴 진단 (0) | 2021.07.13 |
|---|

댓글